DarkMatch: AI-Powered Identity Resolution
DarkMatch outperforms 15 leading identity resolution providers with 28.68% higher match rates and 32-47% reduction in false duplicates. Our multi-stage engine doesn't just match text strings, it understands identity.
How DarkMatch Works
Stage 1: Augmented Deterministic Matching
Stage 2: Probabilistic Fuzzy Matching
Stage 3: AI-Powered Contextual Record Linkage
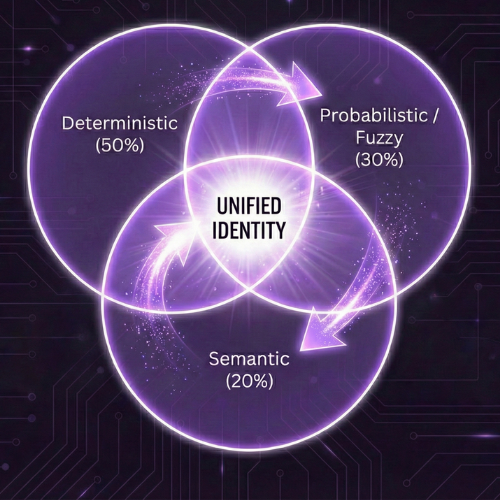
Turn Fragmented Data into Unified Profiles
- 40-50% Higher Match Rates: Find connections that string-matching systems miss through semantic understanding.
- 22% Audience Expansion: Reach qualified prospects with missing data through semantic attribute inference.
- $2.7 million saved: Revenue generated through audience expansion
- Solve the $1 Billion Identity Crisis: Nearly 1 in 4 enterprise customer profiles contain critical errors. DarkMath fixes fragmentation at the source.
Improvement
Improvement
Improvement
Improvement
(False Positives)
Mega-Clusters
Detection
(Baseline)
The Golden Record Output
- True Customer 360: See complete purchase history, preferences, and interactions across all channels
- Accurate LTV Calculation: Understand actual customer lifetime value when fragmented transactions are unified
- Personalization at Scale: Deliver relevant experiences based on complete behavioral history
.png)
DarkMatch FAQs
What data formats does DarkMatch accept?
DarkMatch accepts CSV, JSON, Parquet, and direct database connections. We support batch file uploads, SFTP transfers, S3 bucket sharing, Snowflake table sharing, and REST API integration. No proprietary formats or custom connectors required.
How does DarkMatch handle the 'John Smith Problem'?
Common names are the Achilles heel of traditional matching. DarkMatch treats each identity as a vector centroid and analyzes the full constellation of attributes: spending habits, device usage, location patterns, and life stage. Two "John Smiths" at the same address, father and son, are separated with 99% confidence based on behavioral divergence. The system detects two distinct gravity wells rather than forcing a false merge.
Detailed Example: Semantic Generational Resolution
Consider two records: both "John Smith" at "456 Oak Lane" with the same last name and address. Traditional systems fail here, they either incorrectly merge (corrupting the profile) or require a human to manually review. DarkMath's semantic attribute engine, trained on billions of records with known demographics, identifies the generational signature of each record. Record A shows: TikTok app engagement, Instagram activity, Venmo transactions, casual text syntax with abbreviations ("u" instead of "you"), high emoji frequency, Spotify streaming, and mobile-first browsing. These signals map to Gen Z behavioral patterns. Record B shows: Facebook-primary social engagement, formal email communication, desktop browsing preference, traditional banking app usage, cable TV indicators, and established brand purchasing patterns. These signals map to Boomer generation patterns. Without any explicit "Junior" or "Senior" or age field, DarkMath separates these identities through semantically-trained generational attributes—turning what would be a false merge into two distinct, accurate Golden Records.
Can DarkMatch integrate with my existing matching system?
Yes. DarkMatch is designed to complement existing systems, not replace them. You can run DarkMatch on records that your current system couldn't resolve, use it as a validation layer, or gradually migrate matching logic. Most customers start with a proof-of-concept on a subset of data before full integration.
How do you train your semantic matching models?
DarkMath uses "The Corruptor"—a proprietary synthetic data engine that generates training data by systematically introducing realistic variations into known ground truth records: typos, transposition errors, nickname substitutions, format inconsistencies, and missing fields. This creates massive, unbiased training sets that are mathematically representative of real-world data chaos but free from privacy concerns and historical biases.
Transform your data into Revenue today with DarkMatch
Experience immediate impact with our straightforward integration process and easily measure the benefits of DakMatch