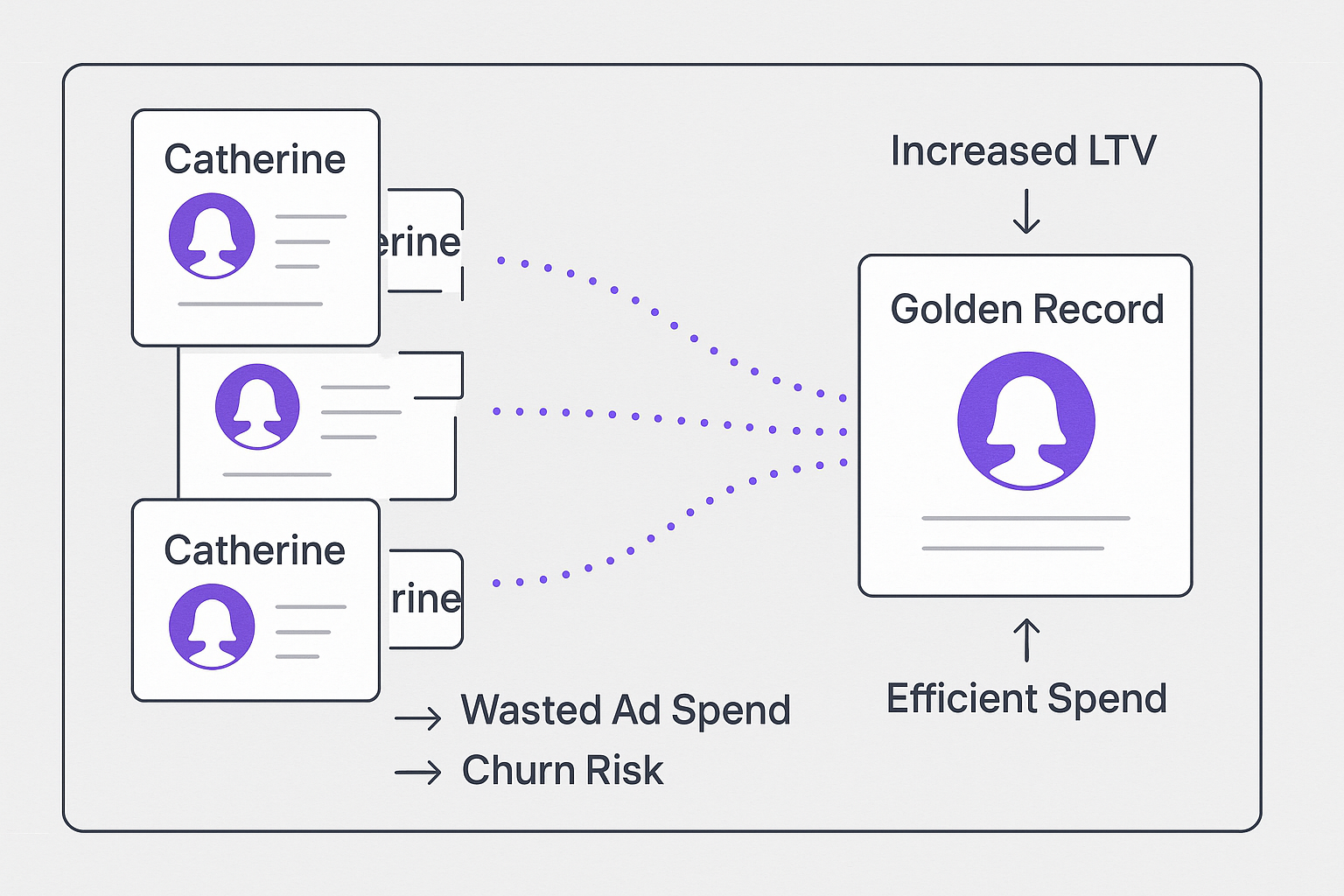
Consider an even trickier identity challenge – two customers with the same name at the same address. John Smith Sr. and John Smith Jr. live under one roof, but one is a 60-year-old executive and the other a 30-year-old grad student. The company’s old system, seeing identical names and address, merges them into one profile (with no awareness of the missing Jr./Sr. suffix). The result is a nonsensical customer record: a single “John Smith” who is seemingly 60 and 30 at once, interested in retirement funds and student loan refinancing, owning a luxury SUV and a used compact. Marketers throw up their hands – this profile is unusable, and trying to market to “him” would likely backfire spectacularly. They effectively discard the profile or treat it very cautiously, meaning both real customers are as good as lost in terms of targeted engagement.
Rule-based approaches often over-merge in cases like this, because they rely on limited identifiers. In the absence of a perfect unique ID, systems use a combination of name and address, etc., to decide matches. That can backfire when two different people share those attributes (a common issue for generational families or even spouses). The consequence is not only wasted marketing spend, but also missed revenue – you can’t effectively sell to a confused, conflated profile. Worse, it can cause customer alienation: imagine sending a promotion for college loan consolidation to the 60-year-old, while the 30-year-old gets an invite to a “Seniors Investment Seminar” because the system thinks they’re one person. Many companies find these situations so troublesome that they spend enormous manual effort to fix them – an average of 1,200 hours of tedious work to resolve identity issues by hand in large databases. Clearly, a smarter approach is needed.
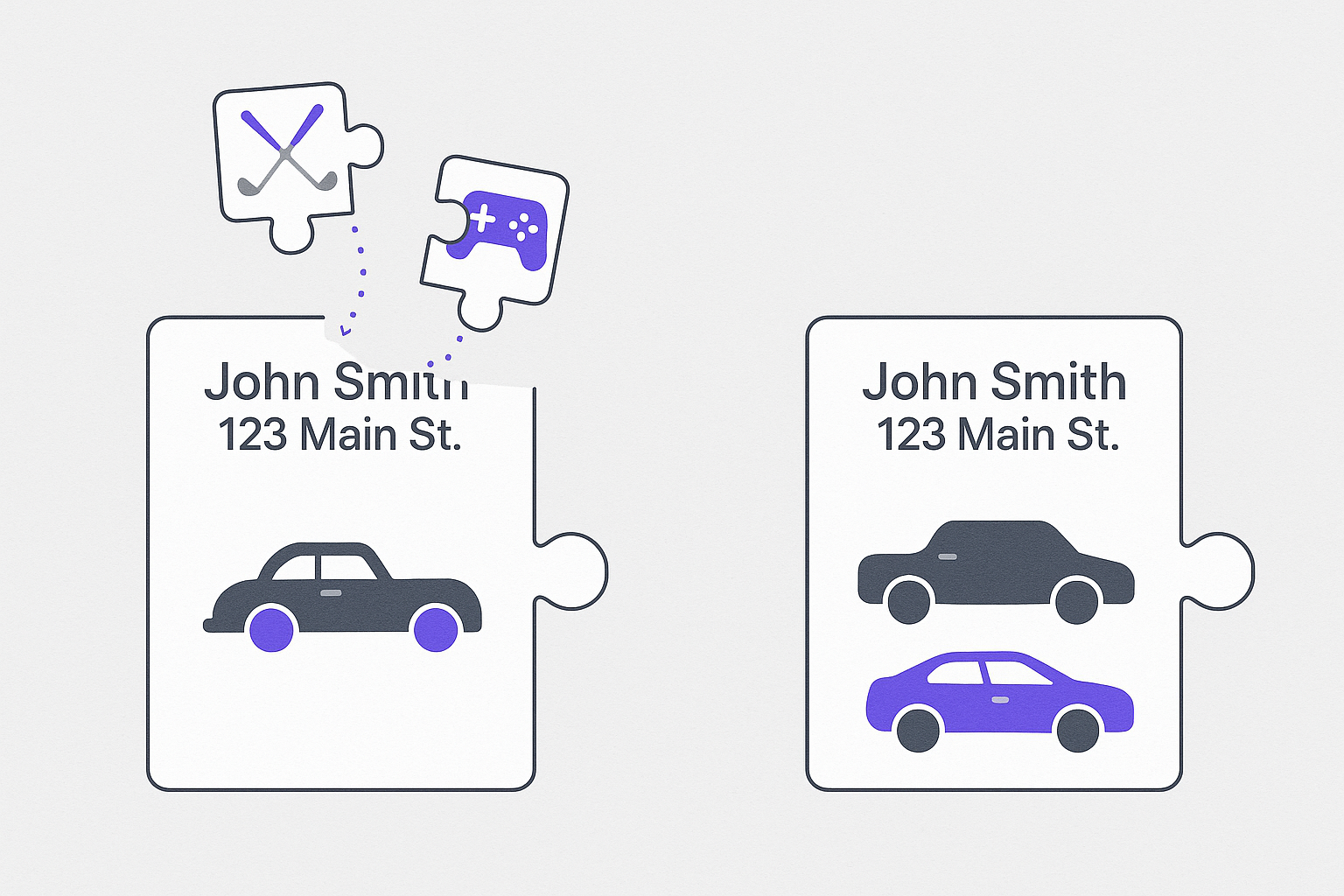
DarkMath tackles the John Sr./Jr. dilemma head-on by looking at the full constellation of data around each John. Instead of naively merging because “name and address are the same,” it asks: Do these records truly represent the same individual? The vectorization engine analyzes hundreds of features. John Smith Sr.’s profile vector might be shaped by data like: a 30-year mortgage, an interest in dividend stocks, a recent purchase of a golf club set, an SUV registered in his name. John Smith Jr.’s data vector might include: a student loan, frequent usage of a gaming console, social media mentions of grad school, a compact car lease.
In vector space, these two “John Smith” records are nowhere near each other – their life stage and behavior patterns differ dramatically. Our system doesn’t need a “Jr.” flag to tell them apart; it infers the distinction from context. DarkMath can go a step further and infer a relationship, then generates new attributes for each profile – e.g., 'Generation = Baby Boomer' for the father, 'Generation = Millennial' for the son, and even 'Relationship = Parent/Child' as a contextual link in the identity graph. These are intelligent attributes that legacy systems would never create on their own.
Two things happen immediately. First, previously “dead” data becomes actionable. What was a single unusable profile is now two high-value profiles with clear, distinctive characteristics. Marketing and sales teams can confidently target each segment: John Sr. can receive retirement planning offers, while John Jr. can be approached with first-time homebuyer loan offers. Instead of avoiding contact, you now have two engaged customers with tailored pitches. This effectively doubles the revenue opportunity from that household with zero increase in acquisition cost.
Second, customer experience improves dramatically. Each John gets messages that make sense for them, enhancing their perception of the brand. This kind of precision targeting drives measurable ROI. One automotive case study found that using data-driven segmentation increased conversion by 24% and online engagement by 36%. Moreover, by eliminating false merges and maintaining accurate profiles, you also mitigate compliance risks and ensure marketing analytics are accurate. DarkMath not only prevents costly mistakes; it unlocks new revenue streams from data you already have, simply by understanding it better.